Le Big Data Expliqué
Jan 25th, 2016Qu’est ce qu’est le Big Data au juste ?
Big Data est un grand mot parapluie qui désigne aujourd’hui tout ce qui touche de près ou de loin à la data dans l’entreprise. Il couvre bien sûr le Machine Learning (algorithmes qui apprennent tout seul à partir des données) mais aussi le Business Intelligence (analyser les données pour mieux comprendre le business) et le Data Management (gestion des base de données et des flux de données).
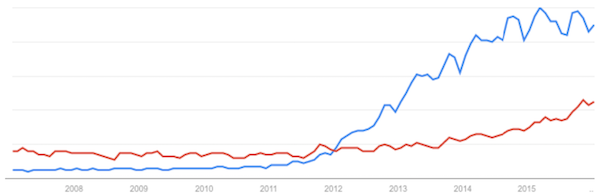 L’utilisation du terme “Big Data” (en bleu) et du terme “Machine Learning” (en rouge) d’après Google Trends.
L’utilisation du terme “Big Data” (en bleu) et du terme “Machine Learning” (en rouge) d’après Google Trends.
Quasi-inexistant avant 2012, le terme “Big Data” a explosé sur 2013-2014 pour se stabiliser en 2015.
Une bonne manière de comprendre ce qu’est le Big Data est de regarder de plus près les métiers qui s’y rattachent. Le Big Data regroupe en fait 3 métiers qui intéragissent ensemble mais qui ont des missions bien différentes.

Le Data Analyst est orienté métier. Il cherche dans les données des insights pertinentes, il creuse, fouille, explique le business à partir de stats. Des exemples de questions auxquelles il doit répondre à partir des données : pourquoi a-t-on vendu moins de chaussettes le trimestre dernier ? quels sont les profils de nos visiteurs ? quelle est la meilleure visualisation de cette stat pour le client ?

Le Data Scientist est orienté maths et algorithmes. Il code des algorithmes de Machine Learning qui répondent à des questions précises, comme par exemple : ce mail est-il du spam ? ce client va-t-il se désabonner du service ? qu’est ce que cet utilisateur peut avoir envie d’acheter ? Il utilise des maths avancées pour construire, évaluer et optimiser ses algorithmes.

Le Data Engineer est orienté infrastructure. Il est l’architecte des flux de données, des serveurs et des bases de données. Il peut être exposé à des problématiques comme : quelle base de données utiliser pour stocker ces données ? comment créer une infrastructure de calcul distribuée dans le cloud ? comment déplacer les données du serveur du client à mon data lake (gros dépôt de données en vrac) ?
La définition tarte à la crème : les 3 V du Big Data
La définition du Big Data scolaire, ultra commune et à côté de laquelle on ne peut pas passer, est celle des 3 V du consultant Doug Laney : Volume, Variété et Vélocité.

Volume : de gros volumes de données. Pour donner des exemples extrêmes : chaque minute dans le monde, 700 personnes réservent un Uber, 110 000 appels Skype sont passés, 600 000 profils sont swippés sur Tinder et 300h de vidéos sont uploadées sur Youtube.
Variété : tout type de données, en vrac. On veut stocker des types de données différents, allant du très structuré comme des bases relationnelles MySQL, au non structuré comme des fichiers CSV, PDF, photos ou vidéos en vrac dans un data lake (Hadoop, Amazon S3).
Vélocité : stockage et traitement toujours plus rapides. Les besoins en vitesse de collecte, stockage, traitement et calculs augmentent, avec comme Graal le temps réel, i.e. la capacité de traiter les données instantanément, sans délai. C’est facile sur des petits volumes mais devient vite très difficile lorsque les volumes augmentent.
Et avec ceci madame, je vous remets quelques V de plus ?

La définition par les V est tellement classique que les experts cherchent à expliquer chaque aspect du Big Data par des V supplémentaires : Véracité (nettoyage du bruit dans les données), Valeur (l’analyse des données doit être motivée par la valeur business qu’elle apporte), Viabilité (chercher les 5% des données qui sont porteurs d’information), Variabilité (présence d’incohérences dans les données) et beaucoup d’autres encore.
On manque cruellement de Data Scientists
Le métier de Data Analyst est vieux et bien défini. On a toujours eu besoin d’analyser les données de l’activité d’une entreprise pour mieux comprendre le business et prendre de meilleures décisions.
Le métier de Data Engineer est celui d’administrateur système appliqué aux problématiques données. Si les challenges et les technologies sont nouvelles, les sysadmins peuvent s’autoformer aux nouvelles technos et les déployer.

En revanche, le métier de Data Scientist est nouveau… et déjà déclaré comme étant “the sexiest job of the 21st century” par la Harvard Business Review. Il existe encore très peu de formations dans le monde, les profils Data Scientists sont rares. Se reconvertir en Data Scientist est difficile : un statisticien doit apprendre à coder et un développeur doit apprendre les maths. Dans les 2 cas, il s’agit de sortir de sa zone de confort et d’apprendre un nouveau métier.
Le Hello World des Data Sciences
Même si pour devenir un bon Data Scientist il vous faudra acquérir de bonnes connaissances en maths et dans divers langage de programmation, son approche est à la portée de tous. Voyons ensemble pour fixer les idées un exemple très simple d’algorithme de Machine Learning qui apprend sur des données et est capable de faire des prédictions.
Jeu de données du Titanic
On part du jeu de données classique des données historiques réelles des passagers du Titanic : un tableau (au format CSV) avec une ligne par passager et ses caractéristiques en colonne : s’il a survécu ou pas (1 survivant, 0 non survivant), son sexe (1 homme, 0 femme), la classe de son billet (1, 2 ou 3), son âge, le nombre de membres de sa famille à bord, le prix de son ticket en dollars.

| Survivant | Classe | Sexe | Age | Famille | Prix |
|---|---|---|---|---|---|
| 0 | 3 | 1 | 22 | 1 | 7.3 |
| 1 | 1 | 0 | 38 | 1 | 71.3 |
| 1 | 3 | 0 | 26 | 0 | 7.9 |
| 1 | 1 | 0 | 35 | 1 | 53.1 |
| 0 | 3 | 1 | 35 | 0 | 8.1 |
| 0 | 1 | 1 | 54 | 0 | 51.9 |
| 0 | 3 | 1 | 2 | 4 | 21.1 |
| 1 | 3 | 0 | 27 | 2 | 11.1 |
| 1 | 2 | 0 | 14 | 1 | 30.1 |
| 1 | 3 | 0 | 4 | 2 | 16.7 |
Classification binaire
La tâche est de créer un algorithme qui apprend à prédire la 1ère colonne à partir des autres, c’est-à-dire à classer les passagers du Titanic en 2 groupes, les survivants et ceux qui n’ont pas survécu, en fonction des caractéristiques des passagers.
L’algorithme va apprendre, pour chaque passager, sur le fichier CSV les liens qu’il y a entre les différentes caractéristiques du passager et le fait qu’il ait survécu ou non. Ensuite, étant donné les informations d’un nouveau passager, l’algorithme pourra prédire s’il va survivre ou non.
import numpy
from sklearn.ensemble import RandomForestClassifier
# lecture du fichier CSV
data = numpy.loadtxt("data.csv", delimiter=",")
# on isole la 1ère colonne "Survivant" des données dans y, le reste dans X
X, y = data[:, 1:], data[:, 0]
# instanciation du modèle
model = RandomForestClassifier()
# apprentissage du modèle sur les données
model.fit(X, y)
# prédiction pour une femme de 50 ans, en 1ère classe,
# ayant payé sa place 70$ et ayant 2 membres de sa famille avec elle
print model.predict([1, 0, 50, 2, 70])
# output >>> 1
# le modèle prédit qu’elle va survivre
# prédiction pour une homme de 25 ans, en 3ème classe,
# ayant payé sa place 6$ et étant seul de sa famille à bord
print model.predict([3, 1, 25, 0, 6])
# output >>> 0
# le modèle prédit qu’il ne va pas survivre
L’internet des objets va décupler le Big Data
Cisco prédit 50 milliards d’objets connectés d’ici 4 ans… Rendez-vous compte. 50 milliards !
Les objets connectés vont des objets électroniques que nous portons (téléphones, montres connectées, bracelets connectés…) aux senseurs industriels sur les lignes de production, en passant par les balances connectées et les colliers pour chats avec GPS.
Chacun de ces objets connectés est une petite usine qui génère des données en continu et qui les envoie dans le cloud. Un déluge de données provenant de ces objets que nos infrastructures vont devoir absorber et analyser. Et tout cela, bien sûr, en temps réel.
De nouveaux challenges passionnants sont à venir.

Faire du Big Data, par où commencer ?
Commencez par stocker toutes les données que vous voyez passer, tous les événements que vous pouvez enregistrer : qui a fait quoi, quand, en combien de temps, dans quelles conditions… Le stockage ne coûte pas cher et même si vous ne vous y mettez que dans 1 ou 2 ans, avoir des données antérieures vous permettra d’aller plus vite.
Pensez Cloud. Les plateformes du type Amazon Web Services sont aujourd’hui matures et permettent de construire une infrastructure puissante et complexe pour seulement quelques heures d’expérience qui ne vont vous coûter que quelques euros.
Par ailleurs, tout le monde ne doit pas nécessairement faire du Big Data. Pour beaucoup d’entreprises, le Big Data n’apporte pas de valeur business. Il s’agit donc d’avoir une réelle réflexion orientée sur la valeur de ce que le Big Data peut apporter, éventuellement avec des experts externes, pour être sûr de ne pas investir dans une mauvaise direction.
Lorsque vous avez des données et que vous êtes convaincu de la valeur business que peut apporter le Big Data, l’idéal est de se faire accompagner par des experts extérieurs pour réaliser une ou deux preuve de concept : faites faire une ou deux preuves de concept (POC) par des experts externes pour confirmer vos intuitions. Il s’agit alors de faire une expérience basique pour confirmer les intuitions et avoir une idées de performances que l’on peut espérer.
Lorsque les résultats des preuves de concept sont concluants, alors vous pouvez passer à la vitesse supérieure et commencer à construire votre équipe Data Science en embauchant des profils spécialisés.
Ai-je assez de données pour faire du Machine Learning ?
La plupart du temps, oui. Par exemple, les 1000 lignes dans le tableau du jeu de données du titanic permettent de construire un algorithme qui retrouve la bonne réponse 80% du temps.

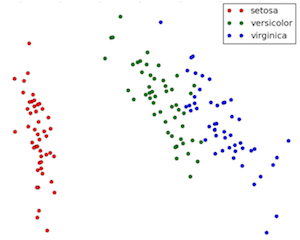
Pour un autre jeu de données, il s’agit de trier des iris (fleurs) en 3 espèces (Setosa, Versicolour et Virginica) en fonction de 4 paramètres pour chaque fleur : la largeur et la longueur des sépales et des pétales.

Avec seulement 150 exemples, on peut construire un algorithme de Machine Learning qui saura reconnaître les 3 espèces dans 95% des cas.
Big Data et vie privée
La première étape si vous collectez des données personnelles de vos utilisateurs, c’est de faire une déclaration à la CNIL (ou de vérifier que vous en êtes dispensés).
Par ailleurs, la loi Informatique et libertés énonce les grands principes de la collecte de données, en particuliers les 3 principes de finalité, proportionnalité et temporalité.
Principe de finalité : on doit dire clairement le but de la collecte des données.
Principe de proportionnalité : on ne doit collecter que les données nécessaires à l’atteinte de ce but.
Principe de temporalité (droit à l’oubli) : on ne doit pas conserver les données après avoir atteint le but.

La philosophie Big Data va quant à elle dans l’autre direction : on aimerait pouvoir tout collecter avant de savoir ce qu’on va en faire, pour pouvoir remonter aussi loin que possible dans les données lorsqu’on imagine une nouvelle application.
Il ne faut pas non plus tomber dans l’extrême en bloquant toute collecte. La recherche en médecine par exemple bénéficie grandement des données personnelles des patients pour étudier les effets des traitements et prévenir les risques. C’est en analysant nos données personnelles que Facebook est capable de sélectionner l’infime partie des informations qui nous intéresse pour nous les présenter sur notre fil d’actualité.
Le cadre de la loi n’étant pas bien défini (on peut choisir un but très général pour collecter toutes les données pour une très longue durée), c’est à chaque entreprise de choisir une politique interne de gestion des données qui relève plus de l’éthique que de la loi.